Override tables can be used to parse long header fields into separate fields. This is helpful, for example, when the job name is embedded in a long header field. The job name can be extracted from the header field, assigned to a field, and used for routing or printing on a banner page. When you create an override table, the parsing command should be entered into the Value field on the Rule Actions dialog box.
The following links provide descriptions and examples of the three methods for parsing data.
The character offset method is used to parse data starting at the first position specified and proceeding until the length specified.
parse(FieldSource, FirstPosition, Length)
FieldSource – The field that contains the string to be parsed.
FirstPosition – The first position of the string to be extracted.
Length – The length of the string to be extracted. If the length specified is zero (0) or if the length is greater than the remaining data, then all data to the last character will be used.
Data: PRINT100STD0C
|
Command |
Result |
|
parse(NDHBDNAM,1,8) |
PRINT100 |
|
parse(NDHBDNAM,9,4) |
STD0 |
|
parse(NDHBDNAM,13,0) |
C |
The single separator method is used parse data based on the delimiter, the field number, and the length.
parse(FieldSource, Delimiter, FieldNumber, Length)
FieldSource – The field that contains the string to be parsed.
Delimiter – The character the marks the beginning and the end of the field. If a comma or backslash is used as the first character of the delimiter, then a backslash must precede the delimiter in the command. For example, a backslash delimiter will be show in the command as \\.
FieldNumber – The first position of the field used for extraction based on the delimiter specified.
Length – The length of the string to be extracted. If the length specified is zero (0), then all data from the FieldNumber through to the last character will be used.
Data: PRINT1,STD,CDATA
|
Command |
Result |
|
parse(NDHBDNAM, \,, 1, 0) |
PRINT1 |
|
parse(NDHBDNAM, \,, 2, 0) |
STD |
|
parse(NDHBDNAM, \,, 3, 1) |
C |
The double separator method is parse data based on the starting delimiter, the ending delimiter, the field number, and the length.
parse(FieldSource, StartingDelimiter, EndingDelimiter, Length)
FieldSource – The field that contains the string to be parsed.
StartingDelimiter – The character that marks the beginning of the string. If a comma or backslash is used as the first character of the delimiter, then a backslash must precede the delimiter in the command. For example, a backslash delimiter will be shown in the command as \\.
EndingDelimiter – The character that marks the end of the string. Again backslash is required when using a comma or backslash as a delimiter.
Length – The length of the string to be extracted. If zero (0) is specified as the length, then the full string between the delimiters will be used.
Data: CJ,P038,FC=6,F=OCR1,ID=J0006600,ACCOUNT=DC
|
Command |
Result |
|
parse(NDHBDNAM, \,F=, \,, 0) |
OCR1 |
|
parse(NDHBDNAM, \,ACCOUNT=, \,, 0) |
DC |
|
parse(NDHBDNAM, \,P, \,, 10) |
038 |
When receiving a print job from a mainframe using BARR/PRINT TCP/IP (the Barr LPD service), the mainframe LPR software often sends a very long job name in the following form:
JESNAME.USERNAME.JOBNAME.JOBID.DATASET.?
For example, the following job name was received from IP Printway, the IBM LPR software:
BAR6JES2.MARKD.APSIVP.JOB08025.D0000108.?
Operators would like to see the actual job name (that is, APSIVP) and the Job ID parsed into a separate fields. This scenario assumes that the user name is already received in another field; therefore, that field will not be parsed.
The parse operation is typically used in an action statement of the Override Table, in the following manner:
FIELD2 = parse(FIELD1,x,1,0)
Here is a sample Override Table that separates out the JESNAME, the JOBID, and finally the JOBNAME into separate fields. JOBNAME is done last because it is configured to write back into the same field from which it came from and actually overwrite the long job name.
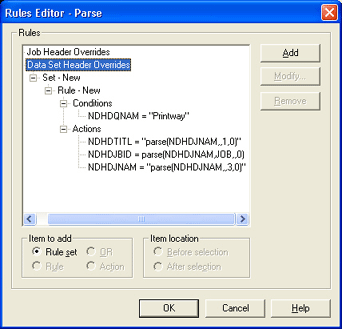
All the actions parse on the NDHDJNAM (LPD Custom Job Name) field.
The first action is a single delimiter parse on the job name using '.' as the delimiter, selecting the first item and putting it into the LPD title field.
The second action is a double delimiter parse on the job name using 'JOB' as the starting delimiter and '.' as the ending delimiter. The value parsed out is placed in the numeric field of LPD Job ID.
The third action is a single delimiter parse on the job name similar to the first action, but taking the third item and putting it back into the job name field, thus overwriting the original long job name. This override uses a condition that applies it only to jobs being received through an LPD queue called 'Printway', but the condition could be left as 'none' to make the actions apply to all incoming jobs.